1.1 前言
做过 java 开发的朋友们相信都很熟悉 HashMap 这个类,它是一个基于 hashing 原理用于存储 Key-Value 键值对的集合,其中的每一个键也叫做 Entry,这些键分别存储在一个数组当中,系统会根据 hash 方法来计算出 Key-Value 的存储位置,可以通过 key 快速存取 value。
HashMap 基于 hashing 原理,当我们将一个键值对(Key-Value) 传入 put 方法时,它将调用这个 key 的 hashcode 方法计算出 key 的 hashcode 值,然后根据这个 hashcode 值来定位其存放数组的位置来存储对象(HashMap 使用链表来解决碰撞问题,当其发生碰撞了,对象将会存储在链表的下一个节点中,在链表的每个节点中存储 Entry 对象,在 JDK 1.8+ 中,当链表的节点个数超过一定值时会转为红黑树来进行存储),当通过 get 方法传入一个 key 来获取其对应的值时,也是先通过 key 的 hashcode 方法来定位其存储在数组的位置,然后通过键对象的 eqauls 方法找到对应的 value 值。接下来让我们看看其内部的一些实现细节。(PS:以下代码分析都是基于 JDK 1.8)
1.2 为什么容量始终是 2 的整数次幂
因为获取 key 在数组中对应的下标是通过 key 的哈希值与数组的长度减一进行与运算来确定的(tab[(n - 1) & hash])。当数组的长度 n 为 2 的整数次幂,这样进行 n - 1 运算后,之前为 1 的位后面全是 1 ,这样就能保证 (n - 1) & hash 后相应位的值既可能是 1 又可能是 0 ,这完全取决于 key 的哈希值,这样就能保证散列的均匀,同时与运算(位运算)效率高。如果数组的长度 n 不是 2 的整数次幂,会造成更多的 hash 冲突。HashMap 提供了如下四个重载的构造方法来满足不同的使用场景:
- 无参构造:
HashMap(),使用该方法表示全部使用 HashMap 的默认配置参数 - 指定容量初始值构造:
HashMap(int initialCapacity),在初始化 HashMap 时指定其容量大小 - 指定容量初始值和扩容因子构造:
HashMap(int initialCapacity, float loadFactor),使用自定义初始化容量和扩容因子 - 通过
Map来构造 HashMap:HashMap(Map<? extends K, ? extends V> m),使用默认的扩容因子,其容量大小有传入的Map大小来决定 前三个构造方法最终都是调用第三个即自定义容量初始值和扩容因子构造HashMap(int initialCapacity, float loadFactor),其源码实现如下1
2
3
4
5
6
7
8
9
10
11
12public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
从源码实现可以看出,如果我们传入的初始容量值大于 MAXIMUM_CAPACITY 时,就设置容量为 MAXIMUM_CAPACITY,其值如下:
1 | /** |
也就是容量的最大值为 2 的 30 次方(1 << 30)。我们知道,HashMap 的容量始终是 2 的整数次幂,不管我们传入的初始容量是什么,它都会使用最接近这个值并且是 2 的整数次幂作为 HashMap 的初始容量,这一步处理是通过 tableSizeFor 方法来实现的,我们看看它的源码:

通过方法的注释我们也可以知道(英语对于从事技术开发的人太重要了~~~),此方法的返回值始终是 2 的整数次幂,它是如何做到的呢?接下来我们通过一个例子一步一步来看,假设我们传入的初始容量大小 cap 的值 cap 为 15。
第 ① 步:将 cap - 1 后,n 的值为 14(15 - 1)。
第 ② 步:将 n 的值先右移 1 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:

第 ③ 步:将 n 的值先右移 2 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
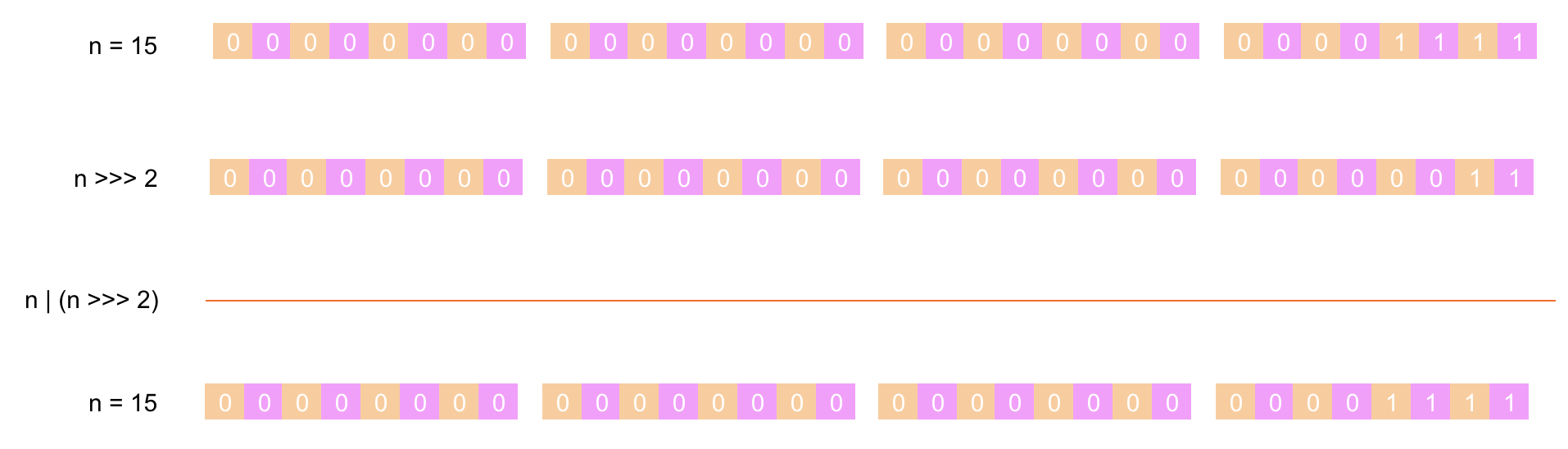
第 ④ 步:将 n 的值先右移 4 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
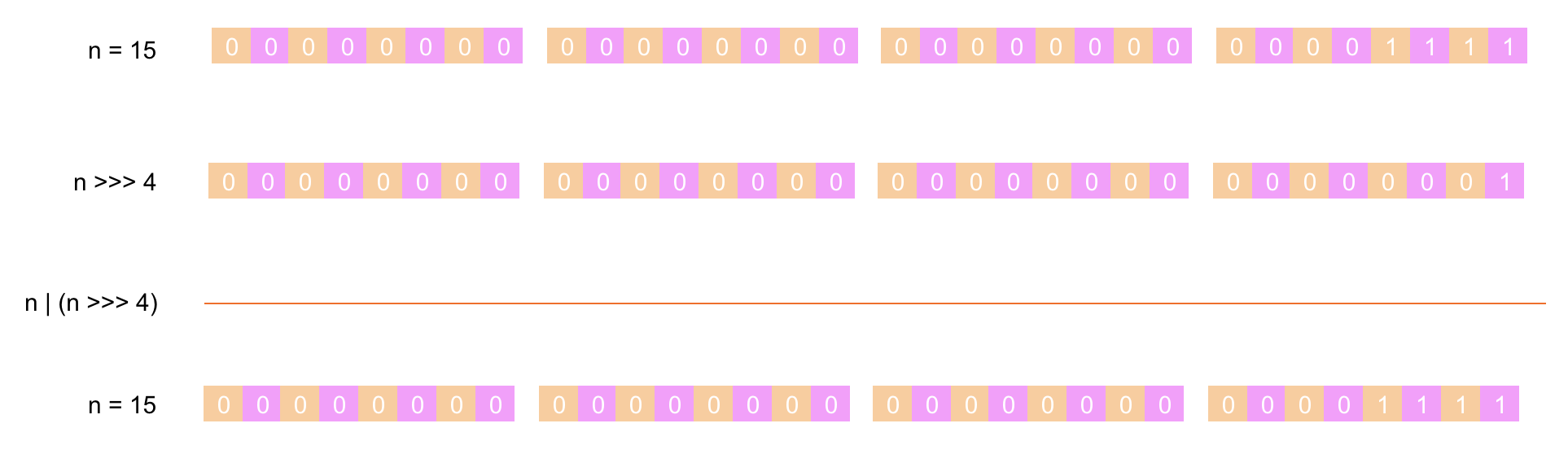
第 ⑤ 步:将 n 的值先右移 8 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:

第 ⑥ 步:将 n 的值先右移 16 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
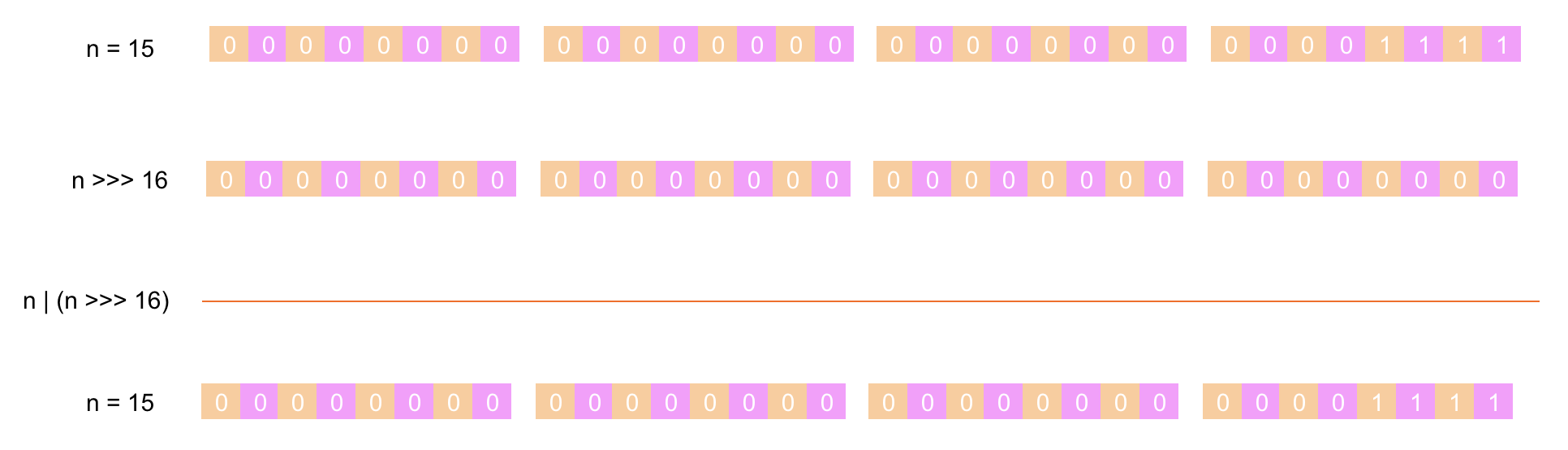
最后如果 n 的值小于 0,则返回 1,如果大于最大值 MAXIMUM_CAPACITY 则返回 MAXIMUM_CAPACITY,否则返回 n + 1。 现在 n 为 15,所以返回 n + 1(16),而 16 正好是 2 的 4 次幂。有的朋友可能会问,刚刚上文假设的初始容量大小 cap 是 15,本来就不是 2 的整数次幂,如果我传入初始容量的就是 2 的整数次幂那会怎么样呢?现在假设传的初始容量大小为 32(2 的 5 次方)看看结果是什么。
第 ① 步:将 cap - 1 后,n 的值为 31(32 - 1)。
第 ② 步:将 n 的值先右移 1 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
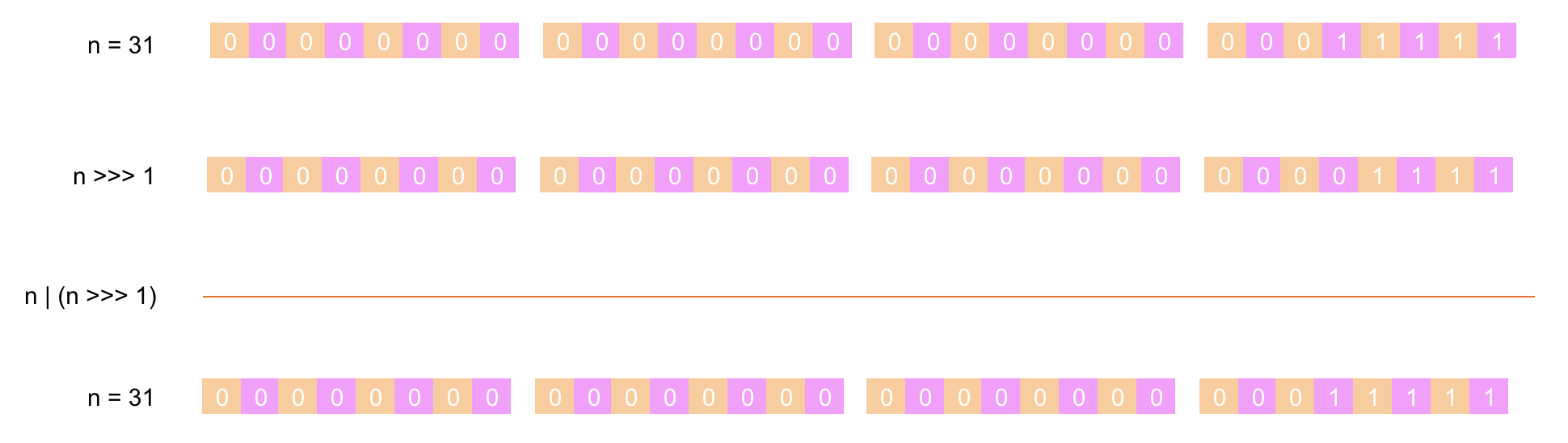
第 ③ 步:将 n 的值先右移 2 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
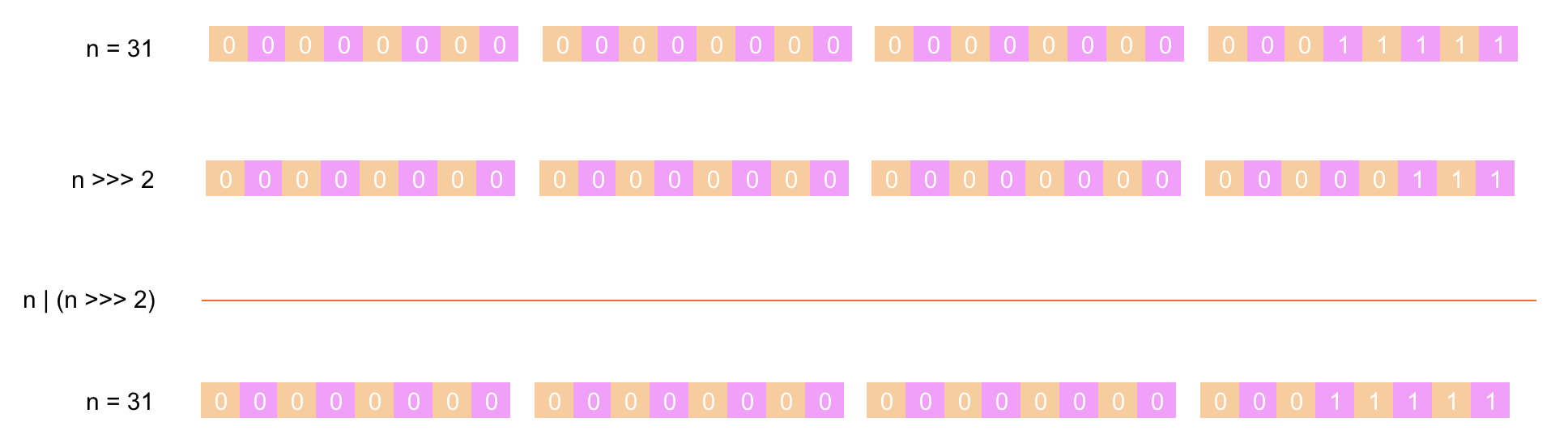
第 ④ 步:将 n 的值先右移 4 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
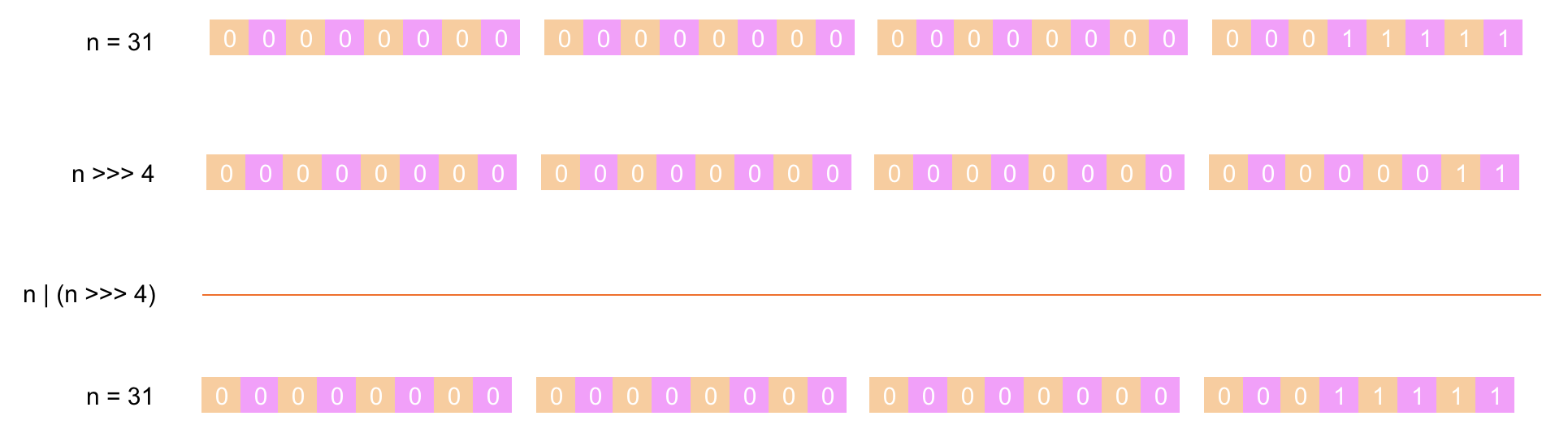
第 ⑤ 步:将 n 的值先右移 8 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
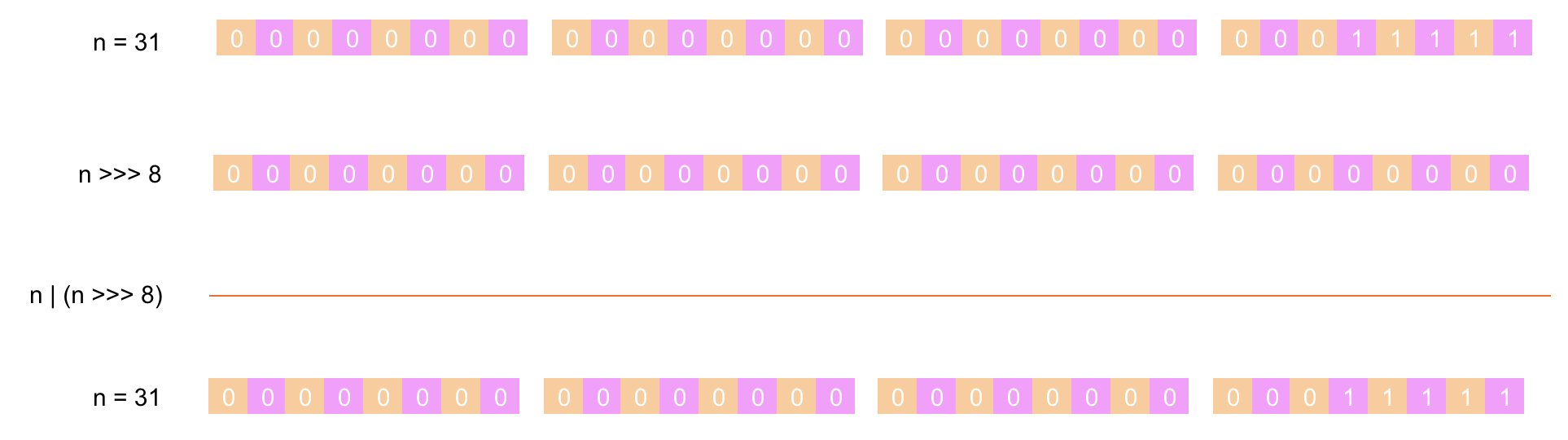
第 ⑥ 步:将 n 的值先右移 16 位后与 n 进行 或运算(两者都为 0 结果为 0,其它情况都为 1),下面是具体的计算过程:
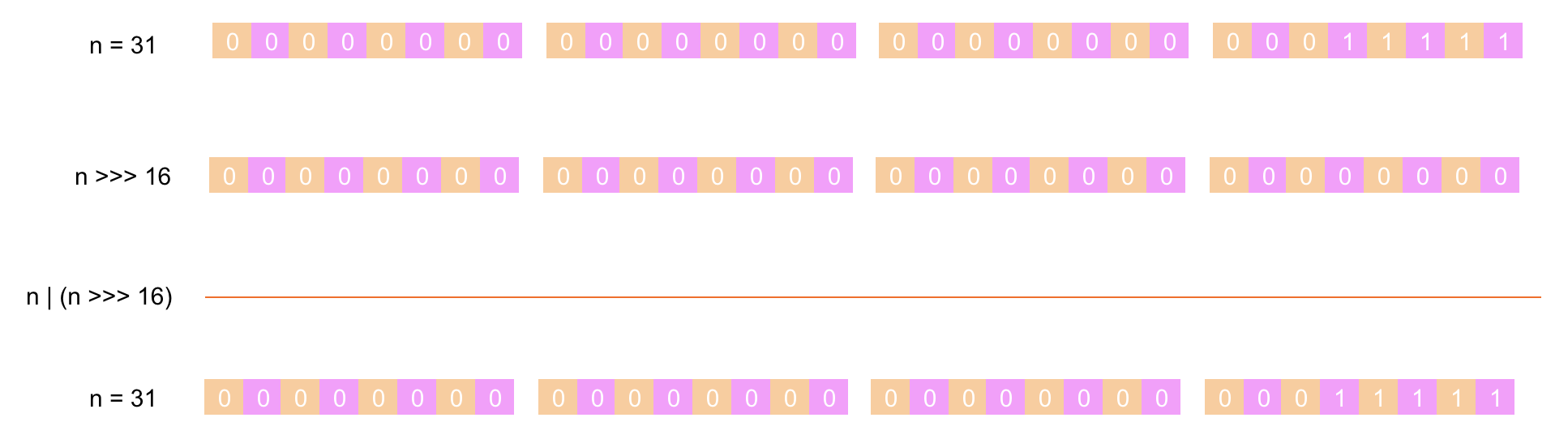
经过以上 6 步计算后得出 n 的值为 31,大于 0 小于 MAXIMUM_CAPACITY 返回 n + 1,所以经过计算后的初始容量大小为 32。稍微总结一下,我们可以得出:如果我们传入的初始容量大小不是 2 的整数次幂,那么经过计算后的初始容量大小为大于我们传入初始容量值的最小值并且是 2 的整数次幂。细心的朋友会发现,为什么第一步要进行 cap - 1 的操作呢?那是因为,如果不进行 - 1 运算的话,当我们传入的初始容量大小为 2 的整数次幂的时候,通过以上步骤计算出来的结果值为传入值的 2 倍。假设我们传入的初始容量大小为 32,此时没有第 ① 步(cap - 1)的操作,那么依次通过以上 ②、③、④、⑤、⑥ 后为 63,最后再进行 n + 1 操作,结果为 64 是 传入值 32 的 2 倍,显然和预期结果(32)不符。这个计算初始容量的算法还是很巧妙的,先进行了 -1 的操作,保证传入初始容量值为 2 的整数次幂的时候,返回传入的原始值。
1.3 hash 方法是如何实现的
不管是通过 get 方法获取 key 对应的 Value 值或者通过 put 方法存储 Key-Value 键值对时,都会先根据 key 的哈希值定位到数组的位置,我们看看 HashMap 里的 hash 方法是如何实现的,源码如下:
1 | static final int hash(Object key) { |
当 key 为 null 时,返回 0,否则进行 h = key.hashCode()) ^ (h >>> 16 运算,先调用 key 的 hashCode 方法获取 key 的哈希值,然后与 key 的哈希值右移 16 位后的值进行异或运算(相同为 0,不同为 1,简称 同假异真),为什么获取 key 的哈希值还要再进行异或运算,直接返回 key 的哈希值好像也没什么问题,如果没有后面的异或运算,直接返回哈希值,我们假设数组的长度为 16,现在要往 HashMap 存入的三个键值对的 key 的哈希值分别为 32831、33554495、2097215,根据 hash 方法返回值定位到数组的位置((n - 1) & hash),以上三个值和 15(16 - 1)进行 & 运算(都为 1 才为 1,其它情况都为 0) 如下:

可以发现以上三个哈希值都定位的数组下标为 15 的位置上。所以 hash 如果方法没有后面与哈希值右移 16 位后的值进行异或运算的话,当数组长度比较小时很容易造成 哈希碰撞,即多个 key(不同的哈希值)都会定位到数组上的同一个位置,也就是说会放入到同一个链表或者红黑树中,因为此时 key 的哈希值只有低位的才会参与运算,显然和我们的预期不符合。可见 hash 方法将 key 的哈希值与其右移 16 位后进行异或运算能减少哈希碰撞的次数,把高位和低位都参与了运算,提高了分散性。
1.4 总结
HashMap 其实还有很多值得我们深入研究的点,看懂了上面两个方法后,不得不佩服作者的代码设计能力,JDK 中有很多优秀源码都值得我们好好品味,看代码的时候一定要多看几遍多问几个为什么,特别是经典的源代码,然后将这些思想运用到我们的实际工作中。


