线程池简介
使用线程池可以很好的提高性能,线程池在运行之初就会创建一定数量的空闲线程,我们将一个任务提交给线程池,线程池就会使用一个空闲的线程来执行这个任务,该任务执行完后,该线程不会死亡,而是再次变成空闲状态返回线程池,等待下一个任务的到来。在使用线程池时,我们把要执行的任务提交给整个线程池,而不是提交给某个线程,线程池拿到提交的任务后,会在内部寻找是否还有空闲的线程,如果有,就将这个任务提交给某个空闲的线程,虽然一个线程同一时刻只能执行一个任务,但是我们可以向线程池提交多个任务。合理使用线程池有以下几个优点:
① 降低资源消耗 多线程运行期间,系统不断的启动和关闭新线程,成本高,会过度消耗系统资源,通过重用存在的线程,减少对象创建、消亡的开销
② 提高响应速度 当有任务到达时,任务可以不需要等待线程的创建,可以直接从线程池中取出空闲的线程来执行任务
③ 方便线程管理 线程对计算机来说是很稀缺的资源,如果让他无限制创建,它不仅消耗系统的资源,还会降低系统的稳定性,我们使用线程池后可以统一进行分配和监控
谈到线程池就会想到池化技术,核心思想就是把宝贵的资源放到一个池子中,每次要使用都从池子里面取,用完之后又放回池子让别人用。那么线程池在 Java 中是如何实现的呢?
Java 四种线程池
在 Java 中 Executors 工具类给我们提供了四种不同使用场景的线程池的创建方法,分别为:
newSingleThreadExecutor只有一个线程来执行任务,适用于有顺序的任务的应用场景。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它,它可以保证任务按照指定顺序(FIFO,LIFO)执行,它还有可以指定线程工厂(ThreadFactory)的重载方法,可以自定义线程的创建行为newFixedThreadPool固定线程数的线程池,只有核心线程,核心线程的即为最大的线程数量,没有非核心线程。每次提交一个任务就创建一个线程,直到达到线程池的最大大小。线程池一旦达到最大值就会保持不变,如果当中的某个线程因为异常而结束,那么线程池会新建一个线程加入到线程池中。它还可以控制线程的最大并发数,超出的线程会在阻塞队列(LinkedBlockingQueue)中等待,同样它也有可以指定线程工厂(ThreadFactory)的重载方法,可以自定义线程的创建行为。newCachedThreadPool创建一个可缓存线程池,最大的线程个数为2^31 - 1(Integer.MAX_VALUE),可以认为是无限大,若无可回收,则新建线程,如果线程池的大小超出了处理任务所需要的线程,那么就会回收部分空闲(60s 不执行任务)的线程。newScheduledThreadPool周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大(Integer.MAX_VALUE:2^31 - 1),适用于执行周期性的任务。
Java 线程池参数详解
上文说到的 Executors 工具类提供的四种适用于不同场景的线程池,通过查看源码可以发现最终都是调用 ThreadPoolExecutor 类来实现的,我们接下来深入了解这个类一些成员变量的具体含义。首先是ctl,其声明如下:
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
这个成员变量 ctl 主要用于存储线程池的工作状态以及线程池正在运行的线程数。很显然,要在一个整型变量中存储两部分数据,只能将其一分为二。其中的高 3bit 用于存储线程的状态,低 29bit 用于存储线程池中正在执行的线程数。
线程池的状态
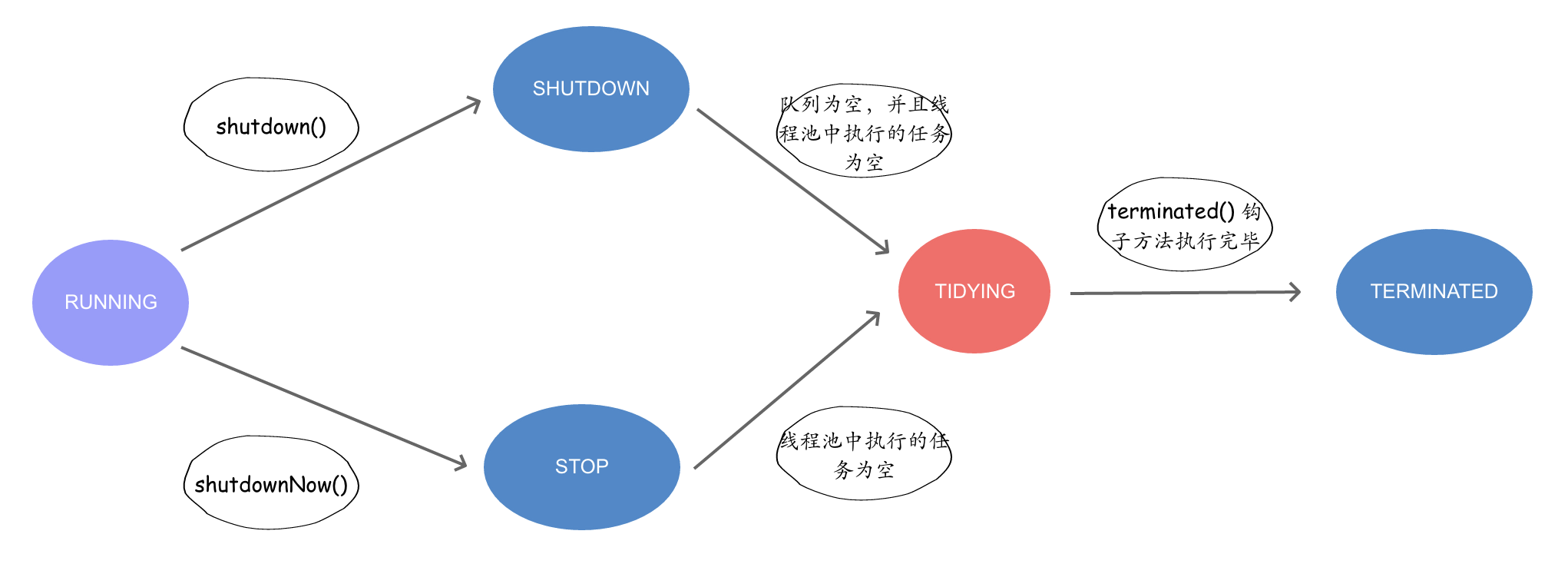
在 ThreadPoolExecutor 定义了线程池的五种状态(注意,这里说的是线程池状态,不是池中的线程的状态),当创建一个线程池时的状态为 RUNNING。
1 | private static final int RUNNING = -1 << COUNT_BITS; |
| 线程池状态 | 含义 |
|---|---|
| RUNNING | 允许提交并处理任务 |
| SHUTDOWN | 不会处理新提交的任务,但会处理完已处理的任务 |
| STOP | 不会处理新提交的任务,也不会处理阻塞队列中未执行的任务,并设置正在执行任务的中断标志位 |
| TIDYING | 所有任务执行完毕,线程池中工作的线程数为 0,等待执行 terminated() 钩子方法 |
| TERMINATED | terminated() 钩子方法执行完毕 |
调用线程池的 shutdown 方法,将线程池由 RUNNING 状态转为 SHUTDOWN 状态。调用 shutdownNow 方法,将线程池由 RUNNING 状态转为 STOP 状态。SHUTDOWN 状态和 STOP 状态都会先变为 TIDYING 状态,最终都会变为 TERMINATED 状态。用图表示为:
ThreadPoolExecutor 同时提供了以下三个方法来查看线程池的状态和池中正在执行的线程数
1 | private static int runStateOf(int c) { return c & ~CAPACITY; } |
ThreadPoolExecutor 的构造函数
该类参数最全的构造方法如下,这个方法决定了创建出来的线程池的各种属性:
1 | public ThreadPoolExecutor(int corePoolSize, |
各个参数的含义:corePoolSize 线程池中核心线程数的最大值maximumPoolSize 线程池中最多能拥有的线程数keepAliveTime 空闲线程存活时间unit 空闲线程存活时间的单位workQueue 用于存放任务的阻塞队列threadFactory 创建线程工厂handler 当 workQueue 已满,并且池中的线程数达到 maximumPoolSize 时,线程池继续添加新任务时采取的策略
下面通过一张图来更形象的理解线程池的这几个参数:
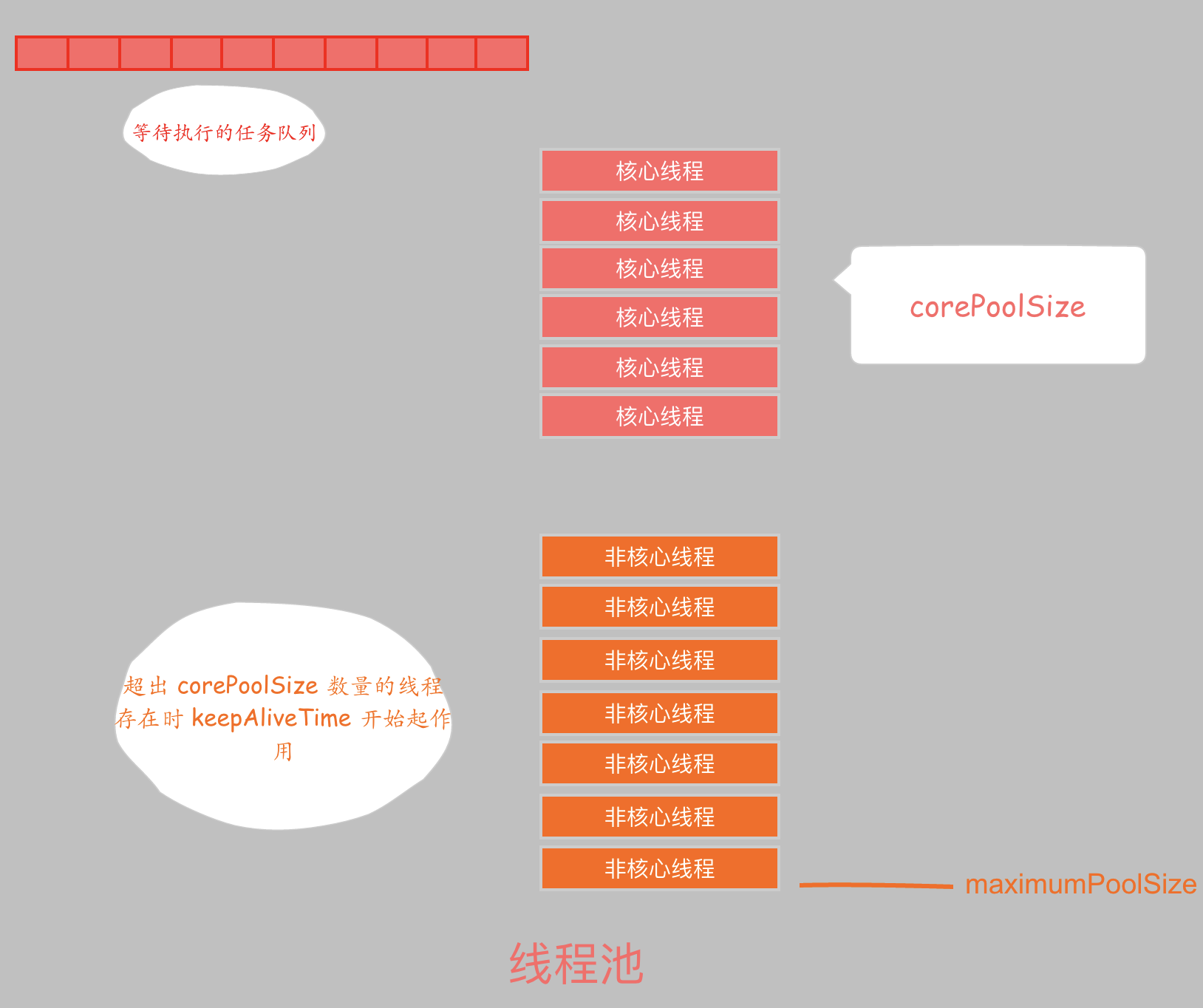
corePoolSize、maximumPoolSize、workQueue 三者的关系,通过向线程池添加新的任务来说明着三者之间的关系:
- 如果没有空闲的线程执行该任务,并且池中运行的线程数小于
corePoolSize时,则创建新的线程执行该任务 - 如果没有空闲的线程执行该任务,并且当池中正在执行的线程数大于
corePoolSize时,新添加的任务进入workQueue排队(如果workQueue长度允许),等待空闲线程来执行 - 如果没有空闲的线程执行该任务,并且阻塞队列已满同时池中的线程数小于
maximumPoolSize,则创建新的线程执行该任务 - 如果没有空闲的线程执行该任务,并且阻塞队列已满同时池中的线程数等于
maximumPoolSize,则根据构造函数中的handler指定的策略来拒绝新添加的任务
在线程池中并没有标记出哪些线程是核心线程,哪些非核心线程,线程池它只关心核心线程的数量。下面这个是网上看到的一个形象的比喻:
如果把线程池比作一个单位的话,
corePoolSize就表示正式工,线程就可以表示一个员工。当我们向单位委派一项工作时,如果单位发现正式工还没招满,单位就会招个正式工来完成这项工作。随着我们向这个单位委派的工作增多,即使正式工全部满了,工作还是干不完,那么单位只能按照我们新委派的工作按先后顺序将它们找个地方搁置起来,这个地方就是workQueue,等正式工完成了手上的工作,就到这里来取新的任务。如果不巧,年末了,各个部门都向这个单位委派任务,导致workQueue已经没有空位置放新的任务,于是单位决定招点临时工吧(临时工:又是我!)。临时工也不是想招多少就找多少,上级部门通过这个单位的maximumPoolSize确定了你这个单位的人数的最大值,换句话说最多招maximumPoolSize – corePoolSize个临时工。当然,在线程池中,谁是正式工,谁是临时工是没有区别,完全同工同酬。
keepAliveTime 和 unit 单位
keepAliveTime 表示那些超出corePoolSize数量之外的线程的空闲时间大于keepAliveTime后就被清除了。
workQueue 任务队列
workQueue决定了缓存任务的排队策略,对于不同的任务场景我们可以采取不同的策略,这个队列需要一个实现了BlockingQueue接口的任务等待队列。从ThreadPoolExecutor的文档中得知,官方一共给我们推荐了三种队列,分别是:SynchronousQueue、LinkedBlockingQueue、ArrayBlockingQueue。其中SynchronousQueue和ArrayBlockingQueue属于有限队列,LinkedBlockingQueue属于无限队列,具体作用如下:
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等待另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。ArrayBlockingQueue:有界阻塞队列。一个由数组支持的有界阻塞队列。此队列按FIFO(先进先出)原则对元素进行排序。新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素。这是一个典型的“有界缓存区”,固定大小的数组在其中保持生产者插入的元素和使用者提取的元素。一旦创建了这样的缓存区,就不能再增加其容量。试图向已满队列中放入元素会导致操作受阻塞,试图从空队列中提取元素将导致类似阻塞。LinkedBlockingQueue:链表结构的阻塞队列,尾部插入元素,头部取出元素。LinkedBlockingQueue是我们在ThreadPoolExecutor线程池中常用的等待队列。它可以指定容量也可以不指定容量。由于它具有“无限容量”的特性,实际上任何无限容量的队列/栈都是有容量的,这个容量就是Integer.MAX_VALUE。LinkedBlockingQueue的实现是基于链表结构,而不是类似ArrayBlockingQueue那样的数组。但实际使用过程中,不需要关心它的内部实现,如果指定了LinkedBlockingQueue的容量大小,那么它反映出来的使用特性就和ArrayBlockingQueue类似了。
threadFactory 创建线程的工厂
其实像ThreadPoolExecutor有的没有threadFactory参数的构造方法中使用的创建线程的工厂就是默认的工厂,比如下面这个构造方法:
1 | public ThreadPoolExecutor(int corePoolSize, |
在这个构造方法中,创建线程的工厂的方法使用Executors.defaultThreadFactory()的工厂和ThreadPoolExecutor中的defaultHandler默认抛弃策略。使用 Executors.defaultThreadFactory创建的线程同属于相同的线程组,具有同为Thread.NORM_PRIORITY的优先级,以及名为pool-poolNumber.getAndIncrement()-thread-的线程名(poolNumber.getAndIncrement() 为线程池顺序序号),且创建的线程都是非守护进程。
handler 拒绝策略
表示当workQueue已满,池中的线程数达到maximumPoolSize时,线程池拒绝添加新任务时采取的策略。从文档中得知,handler一般可以取以下四种值:
| 拒绝策略 | 含义 |
|---|---|
| AbortPolicy | 抛出 RejectedExecutionException 异常 |
| CallerRunsPolicy | 由向线程池提交任务的线程来执行该任务 |
| DiscardPolicy | 直接丢弃当前的任务 |
| DiscardOldestPolicy | 抛弃最旧的任务(最先提交而没有得到执行的任务) |
个人觉得最优雅的方式还是AbortPolicy提供的处理方式:抛出异常,由开发人员进行处理。ThreadPoolExecutor默认的拒绝方式defaultHandler就是ThreadPoolExecutor.AbortPolicy。
合理配置线程池
最后,我们要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质
任务性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。IO 密集型任务则由于需要等待 IO 操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,则将其拆分成一个 CPU 密集型任务和一个 IO 密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的 CPU 个数。
任务的优先级
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
任务的执行时间
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
任务的依赖性
依赖数据库连接池的任务,因为线程提交 SQL 后需要等待数据库返回结果,如果等待的时间越长 CPU 空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用 CPU。建议使用有界队列,有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点,比如几千。有一次我们组使用的后台任务线程池的队列和线程池全满了,不断的抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行 SQL 变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞住,任务积压在线程池里。如果当时我们设置成无界队列,线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。当然我们的系统所有的任务是用的单独的服务器部署的,而我们使用不同规模的线程池跑不同类型的任务,但是出现这样问题时也会影响到其他任务。


